Comment traduire un PDF scanné avec OCR
Vous avez un scan a traduire ? Utilisez notre traducteur PDF en ligne avec OCR pour importer votre document et lancer le traitement immediatement.

Table des matieres
Pourquoi un PDF scanne pose probleme
Un PDF scanne n est pas un document texte classique. Dans la majorite des cas, chaque page est une image. Cela signifie que le systeme ne peut pas traduire directement le contenu, car il ne "voit" pas de phrases exploitables. Sans OCR, vous obtenez un rendu incomplet, des blocs mal interpretes ou des mots ignores. C est la raison principale pour laquelle de nombreux utilisateurs pensent que la traduction d un PDF scanne est mauvaise, alors que le probleme vient souvent de l extraction du texte avant la traduction.
Le deuxieme obstacle concerne la structure. Les scans contiennent des artefacts: ombres, lignes tordues, tampons, contrastes inegaux, marges coupees. Ces elements perturbent la segmentation automatique des paragraphes et des tableaux. Si l OCR lit mal une ligne, la traduction finale herite de cette erreur. C est pourquoi il faut traiter un PDF scanne comme un pipeline complet: qualite du scan, OCR, traduction, recomposition et verification.
Enfin, les enjeux metier sont souvent eleves. Les documents scannes concernent souvent des contrats signes, des annexes juridiques, des dossiers administratifs ou des archives techniques. Dans ces contextes, une petite erreur peut avoir des consequences importantes. L objectif n est donc pas simplement de "traduire vite", mais de produire une version fiable et partageable sans reconstituer manuellement tout le document.
Comment fonctionne OCR et IA sur un PDF scanne
Le flux OCR + IA s execute en plusieurs couches. D abord, l OCR detecte les zones de texte dans l image. Ensuite, il reconstruit une sequence logique de lignes et de paragraphes. Enfin, le moteur IA traduit en tenant compte du contexte. La qualite finale depend de l equilibre entre ces trois etapes: detection, reconstruction, traduction.
Detection des blocs et des zones de texte
La detection identifie titres, colonnes, tableaux et legende. Sur un document simple, l operation est rapide. Sur un scan complexe, elle devient decisive: une mauvaise detection casse l ordre de lecture et melange les paragraphes. Les outils modernes limitent ce risque en croisant plusieurs signaux visuels, mais la qualite du scan reste un facteur central.
Reconstruction des paragraphes
Une fois le texte detecte, le systeme doit recomposer les phrases, la ponctuation et les retours a la ligne. Si cette phase est approximative, la traduction devient hachee. Les meilleurs flux OCR gerent la reconstruction en preservant la hierarchie des titres et la logique des sections, ce qui facilite la relecture finale.
Traduction contextuelle
Le moteur IA intervient ensuite pour traduire en contexte. Contrairement a une conversion mot a mot, il interprete le sens global, le domaine lexical et le ton. Pour un PDF scanne technique ou juridique, cette couche contextuelle est essentielle pour eviter les contresens et garder une terminologie stable dans tout le document.

Pipeline recommande: extraction OCR, traduction contextuelle, verification, export.
Tutoriel pas a pas pour traduire un PDF scanne
1. Preparer le scan
Verifiez d abord la lisibilite. Un scan droit, net et bien contraste donne de meilleurs resultats. Si certaines pages sont floues, rescannez les pages critiques. Supprimez aussi les pages blanches ou les doublons pour accelerer le traitement.
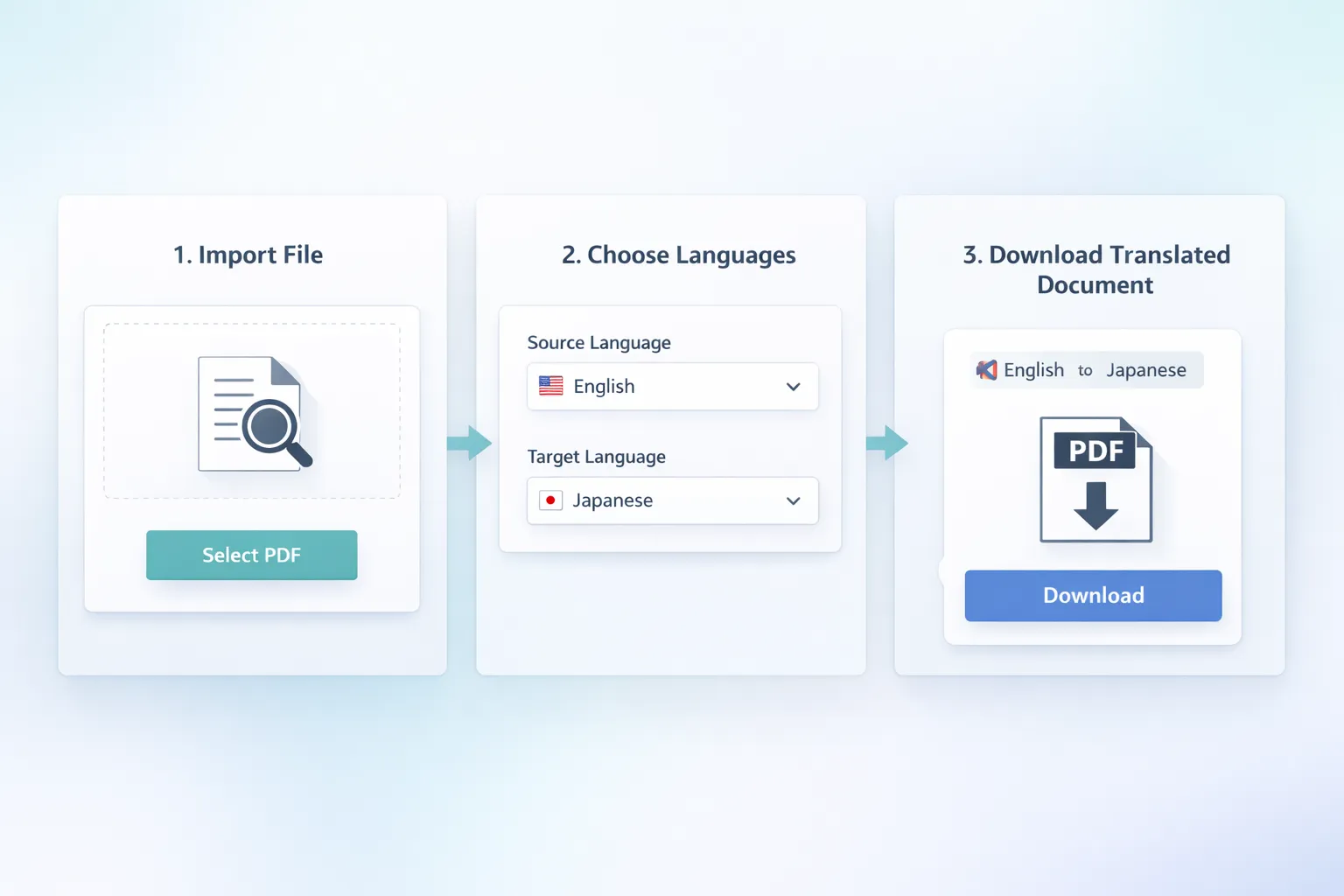
2. Importer et choisir les langues
Importez le PDF puis confirmez langue source et langue cible. Une mauvaise detection de langue peut reduire la qualite globale, surtout sur les documents mixtes. Si votre fichier contient plusieurs langues, traitez par section pour conserver une meilleure coherence.
3. Activer OCR et verifier les parametres
Activez OCR et, si possible, les options de conservation de structure. Pour les documents avec beaucoup de tableaux, activez aussi le traitement dedie aux cellules. Si vous avez un glossaire metier, ajoutez les termes sensibles afin de stabiliser le vocabulaire.
4. Telecharger puis relire
Une fois le traitement termine, verifiez les parties a risque: titres, unites, tableaux, clauses numerotees, noms propres. L objectif est de valider vite, pas de tout reprendre. Sur les documents longs, faites une relecture echantillonnee sur plusieurs pages representant la diversite du contenu.
Methode simple: preparation du scan, OCR + IA, controle final avant partage.
Erreurs OCR les plus courantes
La premiere erreur est de ne pas verifier la qualite des pages avant import. La deuxieme est de supposer que tous les tableaux seront automatiquement parfaits. La troisieme est de livrer sans controle des chiffres et des dates. Ces erreurs ne viennent pas de l IA seule, mais d un processus incomplet. Avec une checklist minimale, elles deviennent evitables.
Une autre erreur frequente consiste a traduire un gros fichier heterogene en une seule fois. Il est souvent plus efficace de decouper par chapitres. Vous obtenez des sorties plus stables et vous corrigez plus rapidement si un probleme apparait sur une section precise.
Conseils pour une precision maximale
Conservez une version source de reference, activez OCR sur les scans, privilegiez les moteurs contextuels pour les textes metier, et imposez une relecture ciblee sur les zones sensibles. Si vous traitez des documents repetitifs, formalisez un protocole interne de verification. Cette standardisation augmente la qualite tout en reduisant le temps global.
Pensez aussi a capitaliser sur les corrections recurrentes. Quand vous identifiez un terme souvent mal traduit, ajoutez-le a votre glossaire d equipe. Sur la duree, ce petit effort cree un gain important et garantit une meilleure cohérence entre vos differentes versions.
Conclusion
Traduire un PDF scanne avec OCR est totalement faisable a condition d adopter la bonne methode. Le couple OCR + IA n est pas une formule magique, mais un process qui marche tres bien quand le fichier est prepare, les parametres sont adaptes et la relecture est ciblee. En pratique, vous pouvez produire des documents traduits fiables en quelques minutes, meme sur des contenus complexes.
Pour valider votre flux, commencez par un document reel et mesurez trois indicateurs: qualite linguistique, stabilite de mise en page et effort de correction. Ce test simple vous permettra de fiabiliser durablement vos traductions de PDF scannes.
Traduire votre PDF scanne maintenant
Chargez votre scan, activez OCR et recuperez une version traduite avec mise en page lisible.