Comprendre la traduction de documents numérisés
La traduction de documents scannés ne doit pas être traitée comme une traduction classique. Quand un PDF provient d un scanner, il contient des pixels, pas des phrases structurées. L OCR reconstruit alors les lignes, détecte les titres, lit les blocs et convertit l image en texte utilisable. Sans cette étape, traduire ce type de PDF donne souvent des segments incohérents, des mots fusionnés et des titres décalés.
Dans un environnement pro, la traduction pdf scanné concerne des cas réels: contrats signés, annexes imprimées, rapports d audit, formulaires administratifs ou supports de formation. Pour traduire un pdf scanné sur ce type de contenu, la priorité est double: précision linguistique et stabilité de mise en page. C est pourquoi notre moteur combine OCR contextuel et traduction IA, au lieu d une simple substitution mot à mot.
Une bonne traduction pdf scanné permet aussi de limiter les risques opérationnels. Lorsque vous devez traduire un pdf scanné pour un client, une équipe interne ou une autorité réglementaire, chaque erreur de sens peut avoir un impact. Avec un flux robuste, vous obtenez un texte lisible, des sections cohérentes et un rendu prêt à validation, sans repasser des heures dans un éditeur externe.

OCR + IA : le flux recommandé pour un rendu fiable
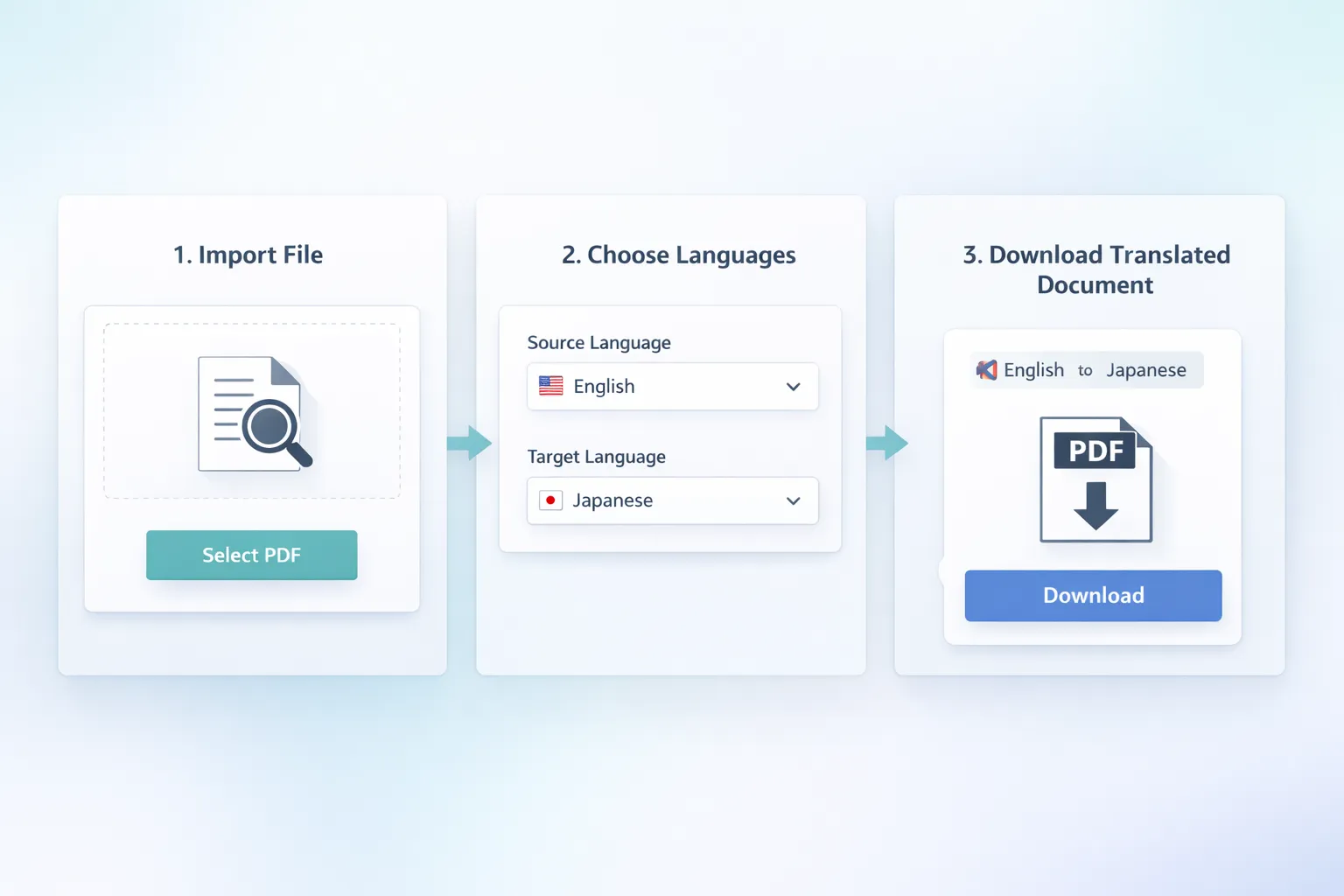
Pour réussir une traduction pdf scanné, il faut suivre une séquence claire: import, OCR, détection de langue, traduction, recomposition. Ce pipeline réduit les erreurs d interprétation et accélère la livraison. Si vous devez traduire un pdf scanné en volume, cette approche standardisée est essentielle pour maintenir un niveau constant de qualité entre plusieurs documents.
L étape OCR n est pas qu un détail technique. Elle conditionne toute la traduction pdf scanné: ponctuation, séparation des paragraphes, lecture des tableaux et ordre des sections. Ensuite, l IA gère le contexte, le ton et les termes métier. Quand vous voulez traduire un pdf scanné contenant du juridique, du médical ou du technique, cette couche contextuelle fait la différence entre un brouillon approximatif et un livrable sérieux.
Notre moteur de traduction pdf scanné est conçu pour limiter les retouches après export. Les blocs restent alignés, les titres restent hiérarchisés, et les tableaux conservent une structure lisible. Cette cohérence visuelle est clé si vous devez traduire un pdf scanné destiné à une diffusion externe, à un audit interne ou à une revue académique.
En pratique, la traduction pdf scanné devient un gain net de productivité: moins de copier-coller, moins d aller-retour entre outils, moins de correction manuelle. Vous pouvez traduire un pdf scanné rapidement, télécharger le résultat, puis lancer la validation métier sans reconstruire tout le document.

Pourquoi choisir notre solution pour les scans PDF
Choisir un outil de traduction pdf scanné ne se résume pas au tarif. Vous avez besoin d une solution stable, rapide et lisible par des non-techniciens. Notre interface simplifie chaque étape et permet de traduire un pdf scanné en quelques minutes, même quand le document original contient des pages longues, des captures ou des annexes.
Nous avons optimisé la traduction pdf scanné pour des usages récurrents: équipes support, opérations, conformité, finance, formation. Si vous devez traduire un pdf scanné chaque semaine, vous gagnez du temps grâce à une sortie homogène et à des paramètres reproductibles. Le résultat reste cohérent entre les fichiers, ce qui simplifie la relecture et réduit les blocages avant livraison.
Enfin, la traduction pdf scanné doit rester exploitable au-delà de la langue. Le document traduit doit être partageable, imprimable et présentable. C est pourquoi notre moteur privilégie la clarté de mise en page en plus du sens. Vous pouvez traduire un pdf scanné pour une présentation client, un dossier administratif ou une publication interne sans repartir de zéro dans un autre logiciel.
FAQ
Peut-on traduire un PDF scanné de faible qualité ?
Oui. La traduction pdf scanné fonctionne aussi avec des scans imparfaits, même si une meilleure résolution améliore toujours la précision OCR.
La traduction PDF scanné conserve-t-elle les tableaux ?
Oui. Notre traduction pdf scanné garde les structures principales et rend le document lisible pour une relecture métier.
Combien de temps pour traduire un PDF scanné complet ?
Cela dépend du volume et de la complexité. En général, vous pouvez traduire un pdf scanné en quelques minutes puis télécharger immédiatement le résultat.